This website uses cookies, pixel tags, and similar technologies (“Cookies”) for the purpose of enabling site operations and for performance, personalisation, and marketing purposes. We use our own Cookies and some from third parties. Only essential Cookies are used by default. By clicking “Accept All” you consent to the use of non-essential Cookies (i.e., functional, analytics, and marketing Cookies) and the related processing of personal data. You can manage your consent preferences by clicking Manage Preferences. You may withdraw a consent at any time by using the link “Cookie Preferences” in the footer of our website.
Our Privacy Notice is accessible here. To learn more about the use of Cookies on our website, please view our Cookie Notice.
Disappearing Development: DIY Review Apps With AWS Fargate and GitLab
Huss El-Sheikh
•11 min read
First we begin, as is traditional for Review Apps it seems, with some acknowledgments. Review Apps are definitely not a new concept. This post is inspired by GitLab’s implementation, which was in turn inspired by Heroku and before that Fourchette by Rainforest QA. I look forward to the next citation in the chain :)
What Are Review Apps?
You can click on any of the links above to go deep into what Review Apps mean to all those different organisations. For the purposes of this post, we’ll simply define a Review App as:
a fully functional deployment of your application/system in an environment dedicated to reviewing updates or changes currently being made to that application/system
Why are they good?
To put it briefly: Feedback. To be able to iterate rapidly and ship frequently, you need feedback. The earlier the better. Review Apps allow us a chance to take a peek, or test features/changes in a fully functional environment. Hopefully spotting bugs, or allowing corrections to be made early in the cycle. Also being able to deploy Review Apps quickly, is what makes them so effective.
How do they work?
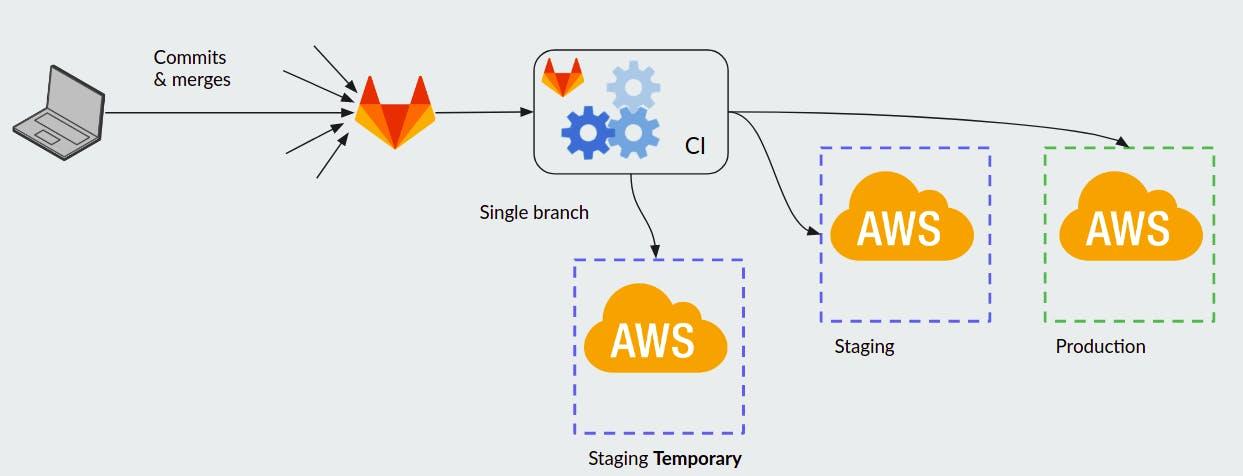
Let’s put this in the context of the Software Development Life Cycle (SDLC)
As development progresses, features are integrated via a Source Control Management System, such as GitLab . Then CI/CD systems take over and build any artifacts for the application before deploying it to an environment where it then runs. In this illustration, first to a staging or test environment, before some “all good” signal is given to then deploy to a production environment.
With Review Apps, the last two steps of staging and production deployments are not performed. Instead, a single isolated change (could be a single commit, feature branch, or an un-merged Merged Request), is deployed to a temporary staging environment.
Great, sign me up!
In the case of our primary DevOps platform GitLab, Review Apps are a built in feature and are available if you also run your applications on top of Kubernetes with their integration . But we run on AWS, and in particular we use ECS to run our applications. This ruled out using GitLab’s off the shelf solution. So I thought, OK we’re halfway there with ECS, we must be able to make this ourselves?
What to Build?
Given enough AWS services it is possible to make anything! But, I was lazy, and wanted to do as little work as possible. The first place to save work, as with the way GitLab do their Review Apps, was to attach our implementation to the various automatic actions which happen on git push/merge events. Using the triggered GitLab-CI system was a good choice for us.
As we already run containerised workloads on ECS, we already have a portable stateless unit of our application. This was already being built and deployed to ECS for us by GitLab-CI. So ECS was a sensible platform to build our solution on.
The Infrastructure
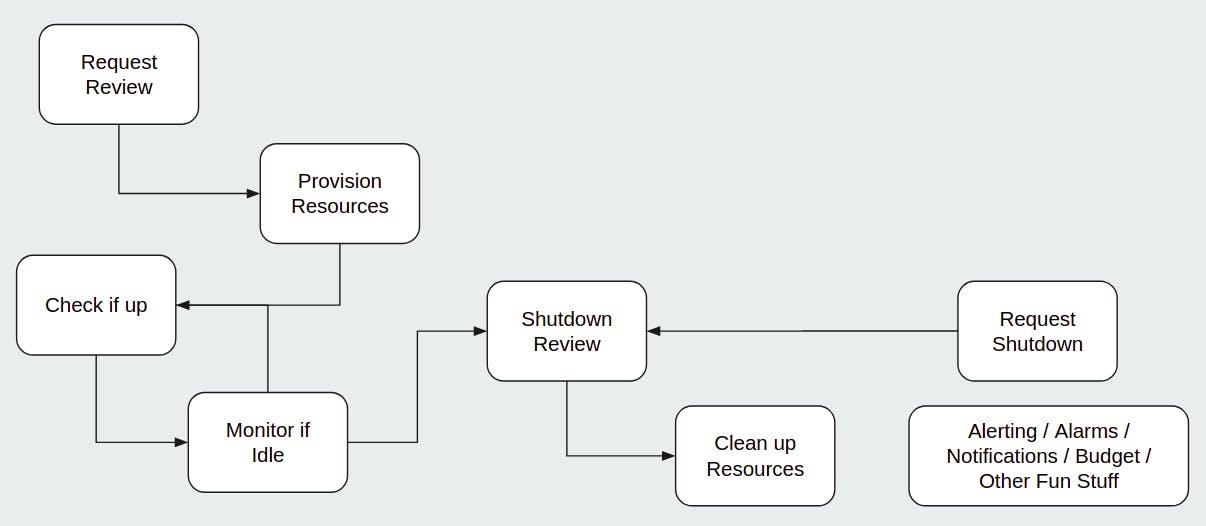
The simplicity of the concept of Review Apps masks the complexity of the implementation. Forgetting about specific vendors, a Review App system must do at least the following:
Listen to events (manual or automated) which trigger a Review App deployment
Build any artifacts for the application, and store them
Provision computing resources to run the Review App
Deploy the Review App
Notify people where to find the Review App
Listen to events which trigger the end of a Review App
Clean up any computing resources
hmmm, this sounds like a lot of work. I’m not into that. How could I avoid as many of these steps as possible?
My Options
a) Provision a small dedicated ECS Cluster for Review Apps
The Good
Don’t need to manage computing resources
The Bad
Caps the number and size of Review Apps without manually adjusting cluster size
Always on EC2 instances, that will be used less than 0.1% of the time…I’m not made of money!
b) Run on “spare” space in other ECS clusters
The Good
Less wasting of computing resources
No guarantee that the IAM policies of the cluster are what we need
The Bad
Now I have to be aware of cluster capacity, and adjust deployments accordingly
Potentially have to dynamically assign IAM roles to clusters, or allow a more open set of security permissions (either suck!)
c) Option A but with spot instances
The Good
Lower absolute cost
The Bad
Spot instance availability is not guaranteed
Changing the size of the cluster is at best manual, and at worst involves setting up ASGs, CloudWatch Alarms and Lambdas all over the place*
*I was wrongly under the impression that I’d not need to do any cluster management with a spot fleet. I thought spot EC2 instances would scale themselves up and down, depending on the workload being run on the cluster. I thought this because I also have an AWS Batch based process, and I can see it has a dedicated ECS cluster which sits at 0 instances until the batch job runs. After a brief back and forth with an AWS SA I met at a partner event, I realised this was some magic sauce AWS Batch does by itself (…probably ASGs, CloudWatch Alarms and Lambdas all over the place).
The “serverless” of ECS, no resources to manage at all
I enter the AWS halls of fame for having a genuine use case for Fargate
The Bad
Fargate does have a price premium per hour over EC2 backed clusters
Finding the Good in the Bad and the Ugly
Out of all the options, D made the most sense for this task. Even if Review Apps were used for 8 hours every working day Mon-Fri, that is still cheaper than the always on EC2 clusters. (You could make it cheaper with Spot Instances and scaling. But that all has to be built and managed by us.)
With Fargate, we do nothing except command the application to exist or not. Given that in reality Review Apps will be on very infrequently relative to the number of working hours in a day, that trade off is worth it. Fargate it was!
Not satisfied with having removed the task of managing infrastructure, I also wanted to not have to manage starting up and taking down the application…am I asking too much?
Well maybe I was, but I had good reason. We can certainly use the GitLab CI process to deploy and start our Review App on Fargate. However, this process runs once and only once. There is no way to keep the job running, or listen to any further outside actions and run further jobs to end the Review App.
GitLab does have a very rich API which lets you do a lot of things, and also has quite a decent set of webhooks you can use in your project. However, this would inevitably mean building something to trigger events, and then also to listen to events in AWS which then control the Review App (see prior comments about “Lambdas all over the place”). I didn’t want to do that either.
I thought it would probably be fine to just let the App run for some period of time and then bring it down regardless. I’d not have to build anything for people to interact with to start/stop the Review App. Such as buttons to click or Slack Chatbots. My assumption is that someone who wants the Review App can trigger its deployment, and will actually want to see it then and there. Plus you can always run the CI job again to relaunch the Review App anyway.
I thought OK, I’ve done a pretty good job of removing a lot of work for this project. Time to stop being lazy and throw up a generic CWEvent + Lambda Setup to bring the app down after some period of time.
Then a Brainwave!
I remembered that with ECS, if you define a Task and not a Service , when the command it was started with exits, the Task is ended. Does this mean that for Fargate, if I start the Review App as a Task, when it stops running that the associated infrastructure would also go away too? To my joy, the answer was YES!
All I needed to do was find a way to end the process after a time limit. Since I’d decided to not build any external system to this, it would have to happen within the the Docker container itself.
Bash to the rescue
The process running within a Docker container is just the result of a command being run by the default shell for the system. This is usually Bash.
At first I Googled things along the lines of “Bash callback script”. There must be something in Bash that can let me execute some other commands in a controlled way I thought? Then I found the timeout command. This utility should be present in most Linux based systems . It lets you write
and have the SIGTERM signal sent to your target command process after the time period ends.
As Jeff Goldblum famously says in the film Jurassic Park: “Bash finds a way”.
Wrapping it all up and Integration with GitLab
If you already use ECS like us, it’s not too much effort to tweak your setup to allow a Fargate cluster to run your workload. We also use the ecs-cli to interact with the AWS ECS services.
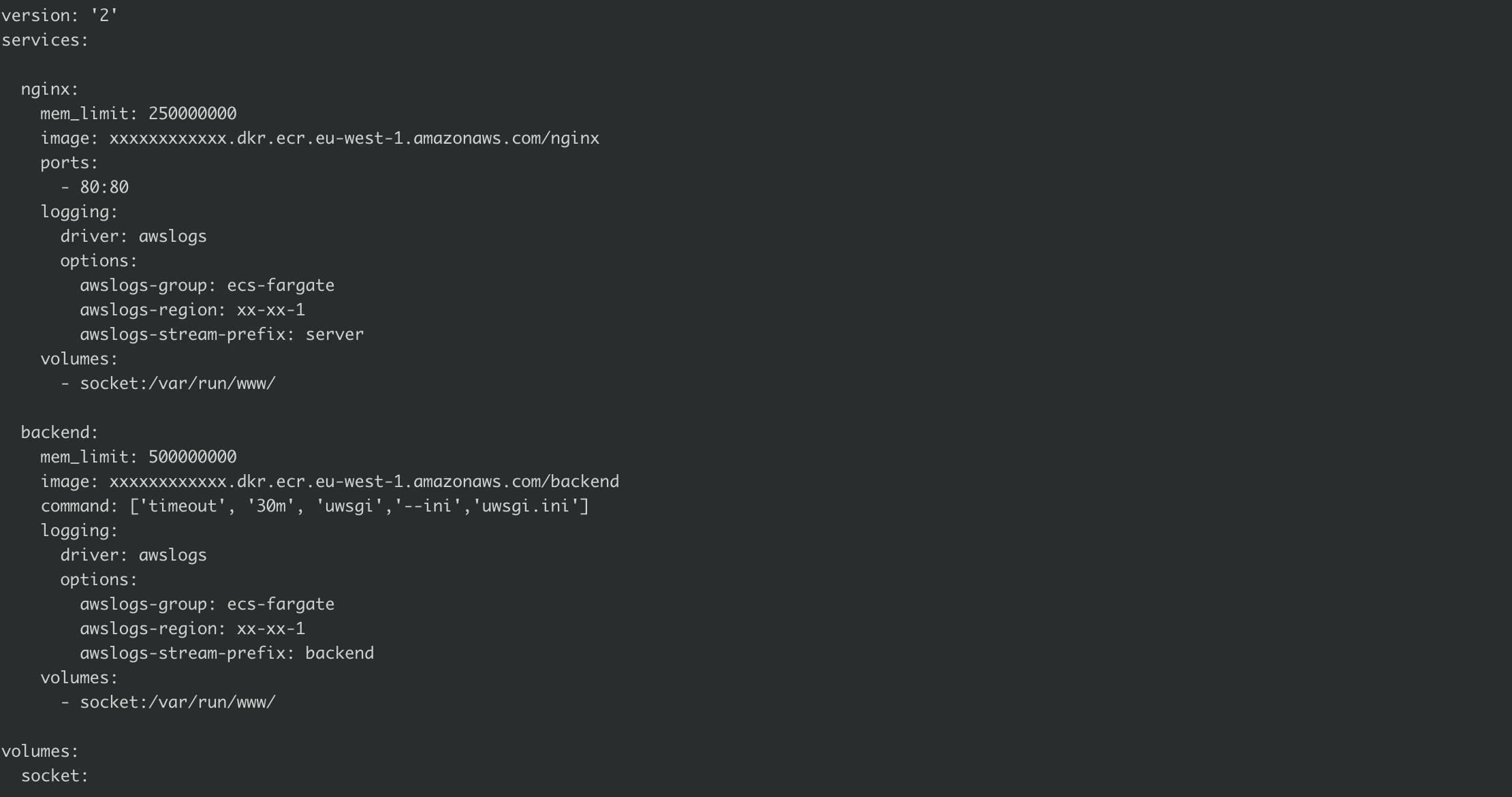
For our demo Review App, let’s take the example of a Python webapp running uWSGI as one container, paired with an NGINX container proxy in-front of it.
This would be our docker-compose.yml file:
Here we have thetimeoutin the command value for the Python webapp. Since some of the values required by Fargate are not supported in the standarddocker-compose.ymlspecifications, we need a furtherecs-params.ymlfile:
Note: If you’re coming from “regular” ECS, then setting up Fargate can be a bit confusing, and introduce some new terms. See this AWS guide for help.
It is very important to mark at least the container which is using the timeout as essential: true. This way, when the command exits, ECS will know that it must exit the entire task and stop all other containers.
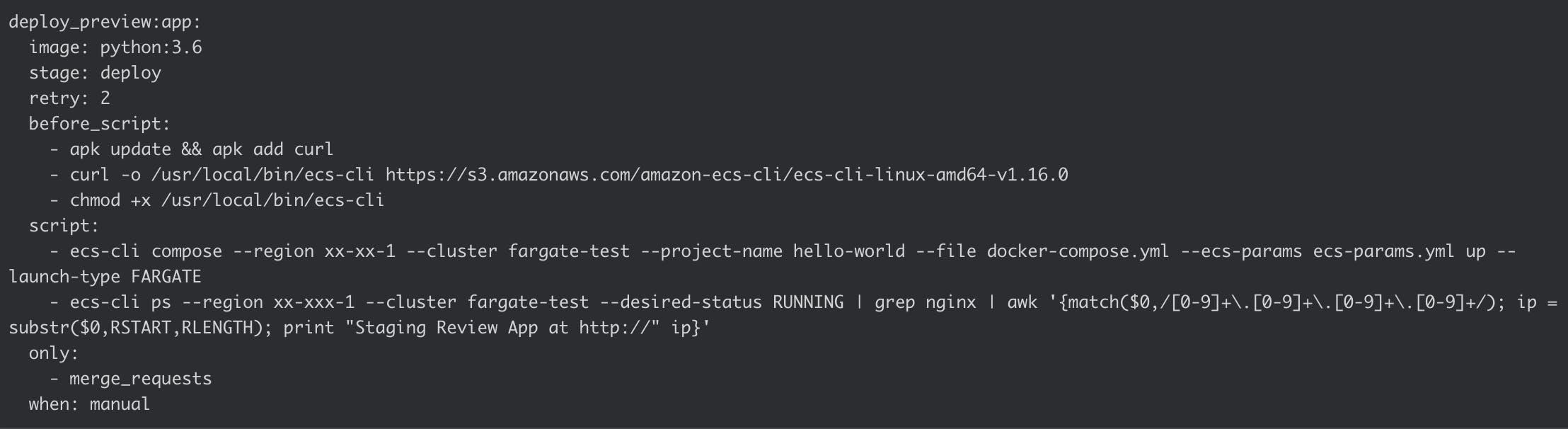
Turning to our GitLab-CI setup, this is the step in our .gitlab-ci.yml which uses the ecs-cli to start the Fargate task:
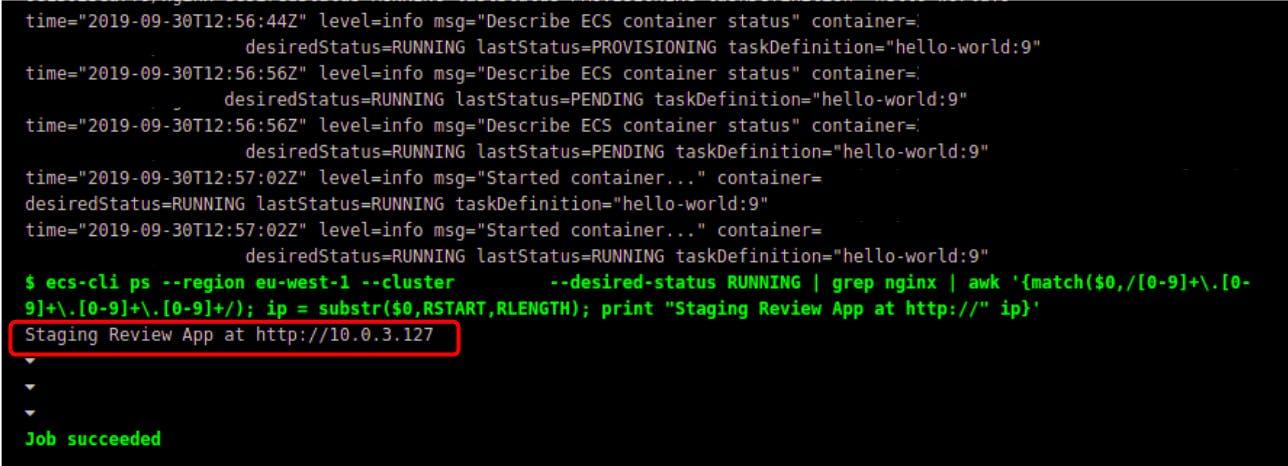
In the script step, the first command is what actually starts the Fargate task using ecs-cli compose. The second command uses the ecs-cli ps command, with some help from grep and awk, to print out the IP of the Review App*.
*If you have deployed your Fargate task in a public subnet, and have assigned it a public IP address. Getting that public IP address is a little bit more difficult. One way is to first get the private IP address as above, and then use the aws ec2 describe-network-interfaces command with a filter applied for that private IP address. Here are a couple of SO answers which talk about it further: 1 , 2 .
Conclusion
What does all this look like to us at 9fin?
Well the end result is that for every merge request, there is an optional gitlab-ci pipeline which allows anyone to run it and deploy a Review App to our staging environment. At the end of the CI job, there is a handy message in the terminal telling you where to go to find this Review App. In 30 minutes, the app will be gone, without a trace.
What did I learn?
My desire to not manage infrastructure for non-critical things is really quite strong. Maybe AWS are onto something with this whole “serverless” thing! Obligatory XKCD.