This website uses cookies, pixel tags, and similar technologies (“Cookies”) for the purpose of enabling site operations and for performance, personalisation, and marketing purposes. We use our own Cookies and some from third parties. Only essential Cookies are used by default. By clicking “Accept All” you consent to the use of non-essential Cookies (i.e., functional, analytics, and marketing Cookies) and the related processing of personal data. You can manage your consent preferences by clicking Manage Preferences. You may withdraw a consent at any time by using the link “Cookie Preferences” in the footer of our website.
Our Privacy Notice is accessible here. To learn more about the use of Cookies on our website, please view our Cookie Notice.
Never Miss a Beat: Centralised Logging for your AWS Lambda Functions with Elastic Cloud
Huss El-Sheikh
•11 min read
Let’s dive straight in! If you are here, you likely are the lucky owner of an ever growing fleet of Lambda functions. What started off as just 1-2 functions for minor housekeeping jobs, has become a sizable operation. With the ease in creating new functions, thanks to frameworks and projects such as serverless, you’ve now come to realise you need a better way to keep an “eye of Sauron” over what’s going on….and how much it’s costing you.
Show me the Money!
This is the only metric I care about really when it comes to our Lambda fleet. I can be pretty confident in the business value they bring to the organisation. (If it’s valuable…it’s being used, if not it goes unused…and is free.) However, the cost attribution AWS provides for Lambda is less than ideal. You will get a single line item for Lambda costs which are combination of invocations and GB-hr costs. Not enough detail for me personally.
It is possible to resource tag all of your functions, then at least you can see a breakdown of costs by function. But, you still lack the ability to analyse on a per invocation level, or to spot statistical transient behavior which may be important during incident investigations.
To reiterate, AWS Lambda provides exceptional business value. If your workload is well suited to it, there is no competition to dedicated a EC2 or other managed services. We are finding ourselves actually reaching for serverless as our preferred way to build systems more and more now. However call me old-fashioned, but I don’t like to roll the dice and see what my bill is each month! I’d just like to know where/how/who/what it comes from, with some level of predictability.
Pssst…don’t forget the other costs which can creep in too. Such at Network Bandwidth if you use VPC lambdas, this also includes NAT traversal costs for when you’re working in private subnets. You have been warned.
Collect all the Logs
I have many views on logs, which are another story for another day. Back to Lambda, have you ever seen this line in your Lambda logs in CloudWatch?
you may also see it without the init duration
Look at all that glorious information. It sure would be great if that was stored somewhere in a structured format for people to query and analyse…… Guess we’re going to have to do this ourselves then.
Getting our (ducks) logs in a row
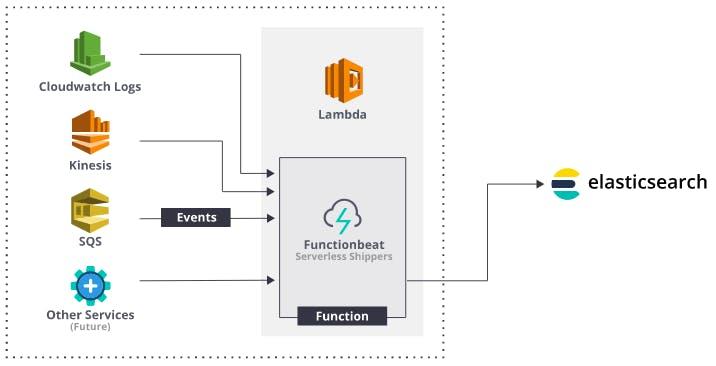
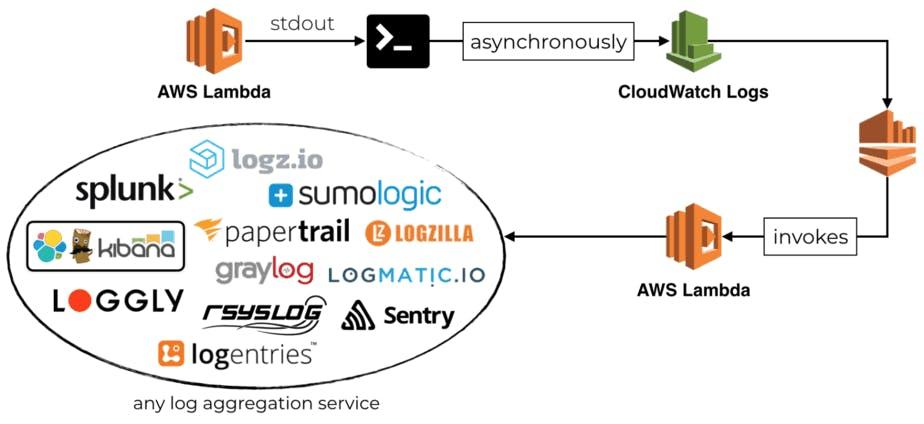
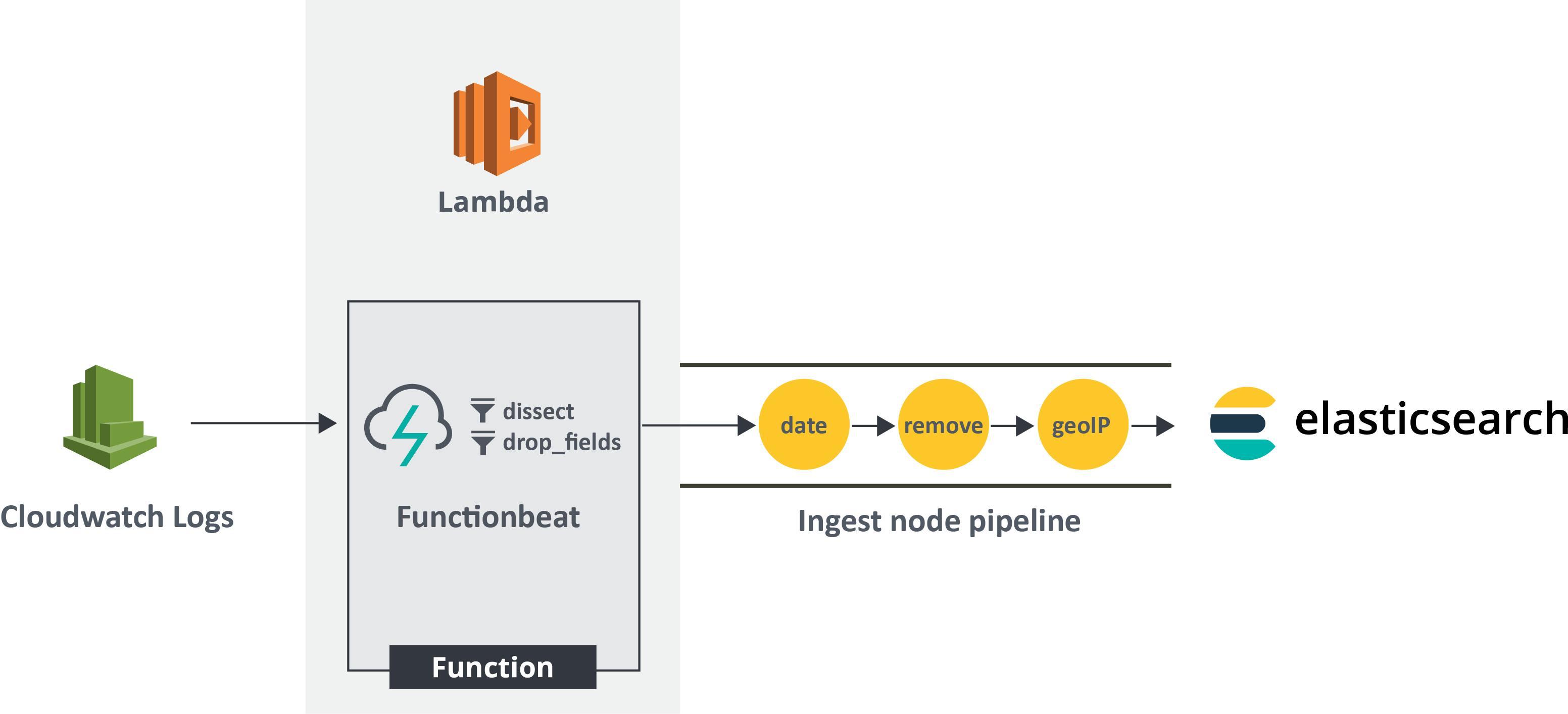
What we’re going to do is a well trodden path. We’re going to funnel all of our lambda logs to once place, then ship them to a different place for storage. The concept is detailed here (If you’re at all serious about serverless, you should read anything by Yan Cui). In the diagram below, from Yan’s post, the final Lambda is in charge of “shipping” the log data to a multitude of different consumers.
There are many commercial SaaS offerings which will do all of the AWS configuration for you. However for us and in this post, we will differ from the above architecture in two ways.
We will be setting up the collection, forwarding, consuming and storage ourselves. (Since I don’t think it’s that difficult, and also due to my yet to be disclosed feelings about logs, these services have limited value for me.)
For the final Lambda, which does the “shipping”, we will be using a Functionbeat . This is still a Lambda, but one provisioned by the Elastic Beats platform, and is dedicated in shipping logs (or other data) to Elasticsearch from serverless functions.
The general flow is like so:
We will be sending the “REPORT” log line from our Lambdas, parsing and extracting the data points within it, and then storing in Elasticsearch.
I will point out now, that AWS does have a product called CloudWatch Logs Insights . Where you can query your logs, and it can pull structured information out of them. Here is an example doing just that for Lambda logs. The interface is very reminiscent of AWS Athena , so I have my suspicions as to how CWLogs Insights works under the hood. However for us the goal is not to enumerate every single log line, but rather to just pick out the one we need.
In the following section I will detail the steps necessary to setup this system yourself. When I first did it, I was following the Getting Started guide from Elastic. But I found myself with 10 tabs open by the end of it, over both AWS and Elastic docs, as I had to cross check and re-read things. In my view the Serverless project, is the Gold Standard in developer tooling and experience. There is room for improvement here for Elastic, so I hope I’m able to outline things in an order that makes sense, and does not leave you scratching your head.
The Simple Steps to Success
You will need;
access administer to your AWS account and resources
access to administer your Elasticsearch cluster (I’ll use the Kibana Dev console).
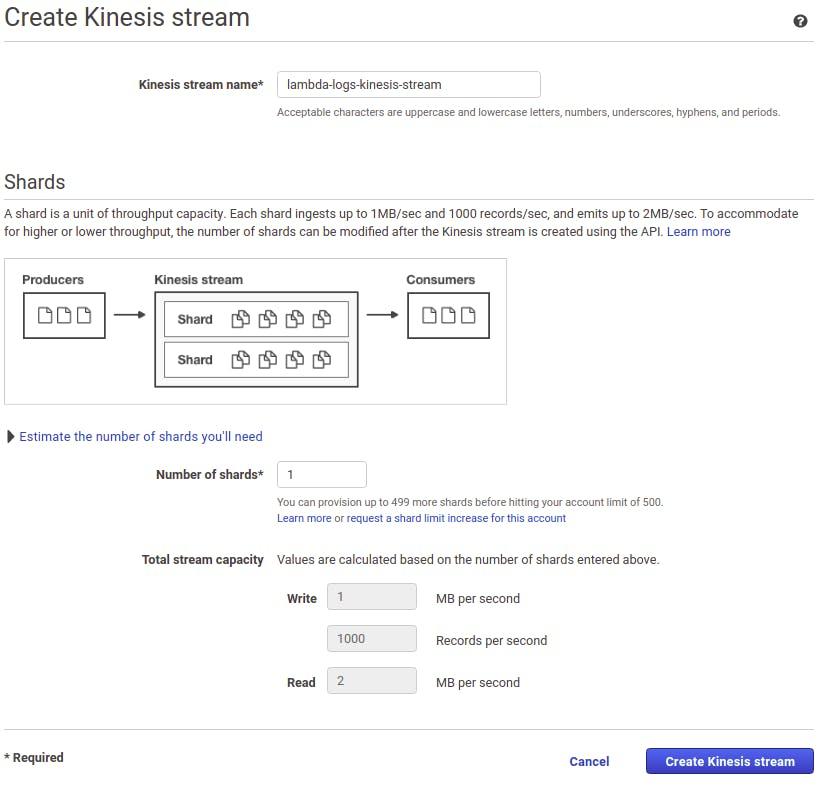
1. Setup a Kinesis Data Stream
Using your preferred method, cli or console, create a Kinesis Data Stream. Give it a name, and let’s go with just 1 shard for now.
While in AWS, we can do some preparation work to get ready to send logs to the Kinesis stream. Follow Example 1 here , and do steps 3-6. Now you will have the correct permissions in place to allow CloudWatch to send your logs to the Kinesis stream.
Make sure you swap in your region, aws account, and kinesis Stream name.
2. Create your Functionbeat project
Create a new directory for your Functionbeat to live in. From within that directory, run the snippet below to pull down and extract the Functionbeat distribution.
Unlike the Serverless framework, which is installed globally as a utility. The Functionbeat distribution includes actual binary files which need to be present locally so that they can be zipped up and pushed up as part of your Functionbeat Lambda deployment.
The two files you need to care about are
functionbeat: this is the binary which is also the cli tool. We’ll use it to configure/deploy/update/delete our function
functionbeat.yml: this is where we declare the various settings on our Functionbeat.
3. Setup Functionbeat users and permissions
Before getting to configuration, first set up the Elasticsearch cluster user that the Functionbeat will connect with. There is some information about security and roles in the docs , but I found it slightly confusing. The functionbeat cli tool in your local directory is capable of both carrying out privileged setup actions as well as when deployed doing the actual log “shipping” - which requires lesser permissions. I advise to set up a user just for when the Functionbeat is running, and to do all the privileged actions via Kibana or the cluster http API with your own superuser or appropriate role. This keeps things cleaner.
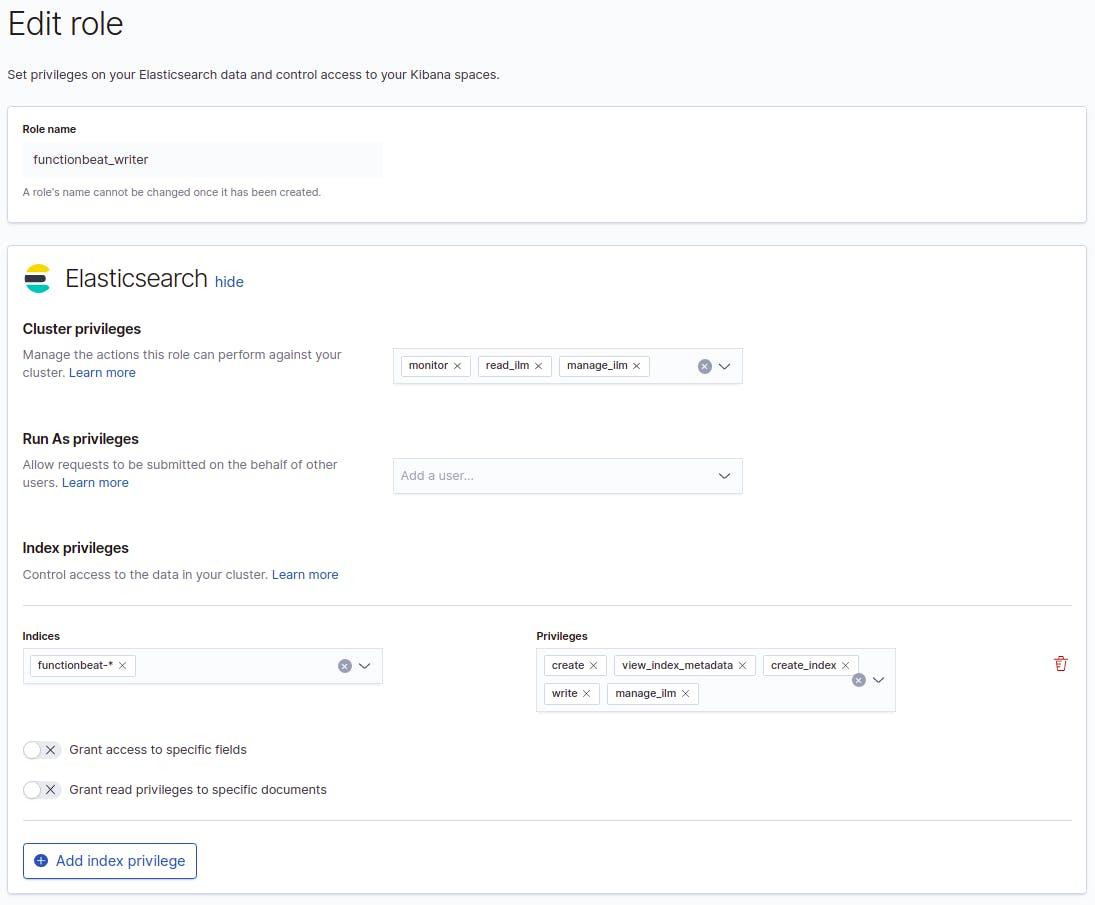
4. Create User and Role
Let’s set up a user and role for the Functionbeat to run with. Create a role functionbeat_writer, with privileges as shown below.
Then create a user, such as, functionbeat_user and assign the functionbeat_writer role to it. You may also assign the built-in beats_system user to it, if you plan on enabling monitoring.
The message from Elastic on using the beats_system role is fuzzy. Here it says not to use it, but here it does. Things seem fine so far for us so… ¯\(ツ)/¯
5. Configure
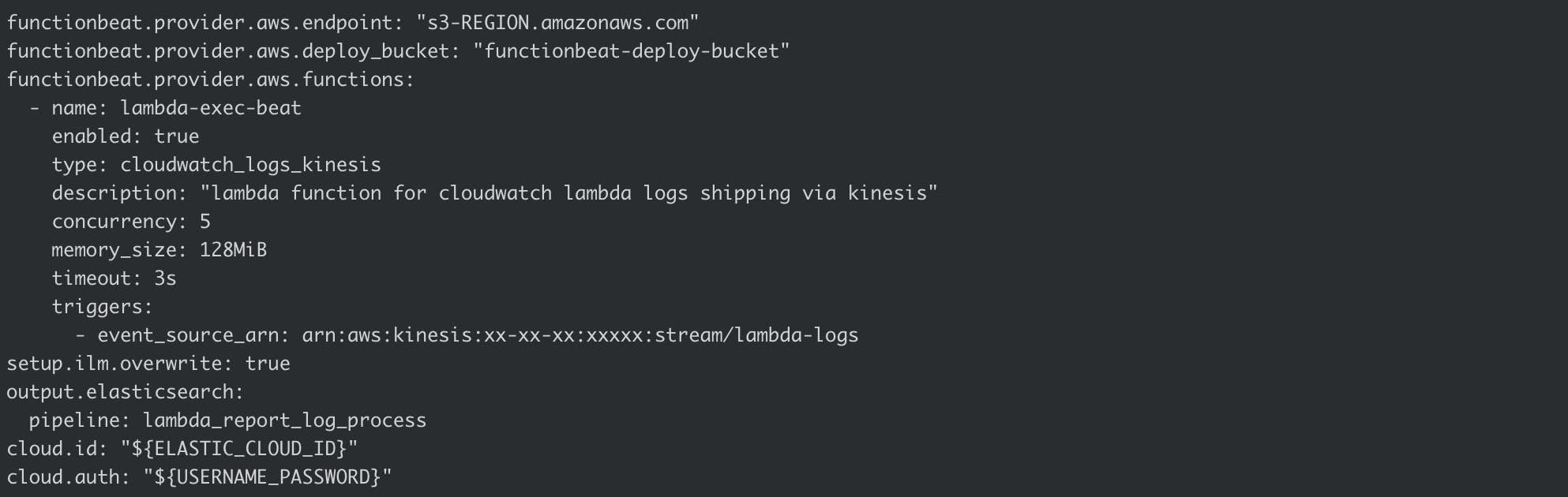
Following step 2 (of the Functionbeat guide), for a Kinesis integration, you should end up with a config file that looks like this.
remember to use your newly created Functionbeat user e.g. export USERNAME_PASSWORD=functionbeat_user:XXXXXXX
You may not be running in Elastic Cloud, if so, you’ll need to define the output.elasticsearch section explicitly with host, username, and passwordvalues.
Secrets are provided via environment variable interpolation. Currently there is an open issue with using the “Keystore” feature as it does not work with a deployed Functionbeat in a cloud environment.
As with any Eleaticsearch index, we need to define the index settings and mapping. We do this by installing the template as described in step 3 . But as this is a privileged action, we will run this directly against the cluster ourselves.
First generate the template as a json file:
then install it on the cluster (via the Kibana console):
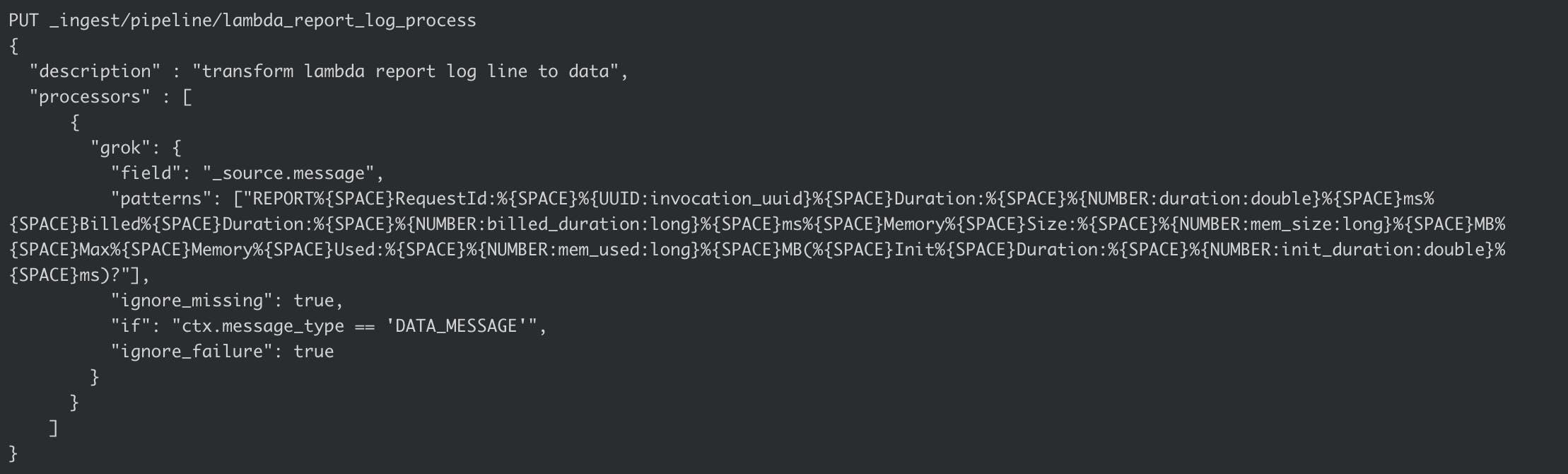
6. Setup an Ingest Node Pipeline
An ingest node is a property of your index, not of the Functionbeat. It is basically a bit of logic which intercepts all data heading to be stored in your index, where it can be processed before the document is actually stored.
In our case, this is the actual step which transforms those plain text log lines (REPORT RequestId: cf697...etc) into structured data attributes. We will use the GROK processor, and the ingest pipeline is defined and installed into the cluster as below:
There is only 1 pattern we are testing for. Feel free to go to any online GROK tester to play around and test it against your Lambda log lines.
The only things to highlight are that we use the${SPACE}pattern at all possible space locations because sometimes there can be a mix of tabs and spaces. This is the safest thing to do, so that all whitespace is considered. Second, the last pattern is wrapped in(...)?, this is because theInit Durationis only present on cold-starts, so we need to mark it as optional otherwise the pattern fails when it is not present.
7. Deploy your Functionbeat
Following step 4 , Deploy with the command:
8. Activate Log Group Kinesis Subscriptions
With the Functionbeat up and running, we can now subscribe a log group to our Kinesis stream. To do this, issue the command below with the aws cli
The filter pattern is used to allow only a subset of your logs to actually be forwarded to the Kinesis stream. This is useful to reduce unnecessary executions. There are many filter patterns you can define.
Did it work?
Well I hope so. To validate everything is flowing through nicely, when you know you that some Lambda invocations have happened, you can check the data.
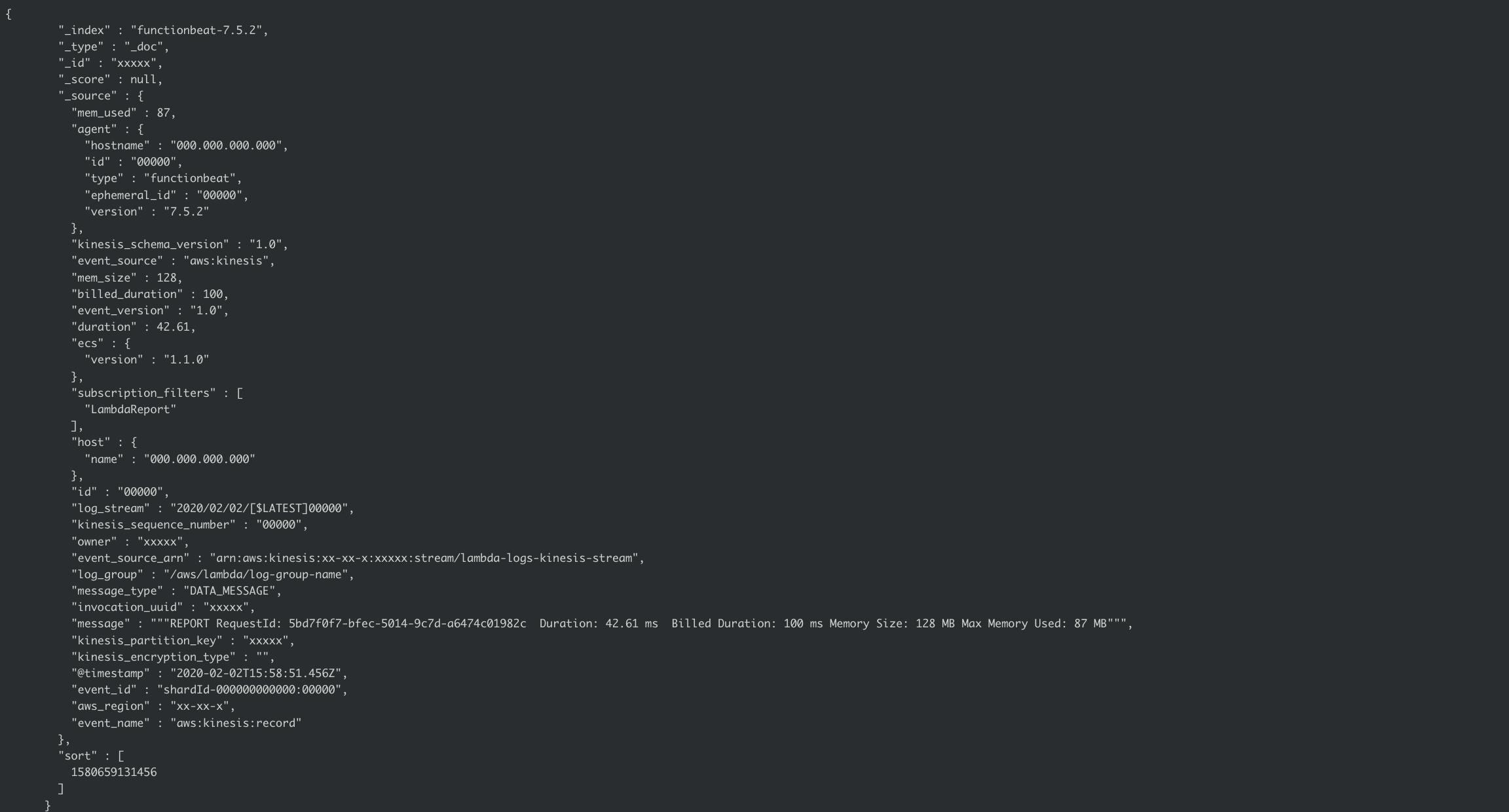
In the Kibana console, run a search for the latest documents:
and you should see documents like this:
The fields we pulled out via the GROK processor are in the document too:
You may also see some documents with the field "message_type" : "CONTROL_MESSAGE". These are like “keepalive” or “ping” messages which are used by the underlying AWS systems to make sure everything is OK. It’s fine to ignore these.
Success! Where next?
Well, there are a lot of settings in the Functionbeat configuration , reading through them all is not bad idea.
Then, one way we could optimise the process further is by dropping the message field after the GROK pipeline has run. We no longer need this text string, so it would save us space in the index. This processor could be defined as part of our ingest node like so:
Visualise!
Now that the data is streaming into Elastic. Why not use Kibana to setup dashboards to monitor crucial Lambda metrics such as duration, memory and cost. We will do just that in part II of this post.